公开资料显示,Stable Diffusion是StabilityAI公司于2022年提出的,论文和代码都已开源。StabilityAI在10月28日完成了1.01亿美元的融资,目前估值已经超过10亿美元。大家可以去Stable Diffusion Online这个网站体验一下Stable Diffusion,我们输入文本“’A sunset over a mountain range, vector image”(山脉上的日落),看一下效果:在了解应用后,接下来我们介绍下Stable
公开资料显示,Stable Diffusion是StabilityAI公司于2022年提出的,论文和代码都已开源。StabilityAI在10月28日完成了1.01亿美元的融资,目前估值已经超过10亿美元。
大家可以去Stable Diffusion Online这个网站体验一下Stable Diffusion,我们输入文本“’A sunset over a mountain range, vector image”(山脉上的日落),看一下效果:
在了解应用后,接下来我们介绍下Stable Diffusion。主要还是通过图解的方式,避免大量公式推导,看起来费劲。
1. Stable Diffusion文字生成图片过程
Stable Diffusion其实是Diffusion的改进版本,主要是为了解决Diffusion的速度问题。那么Stable Diffusion是如何根据文字得出图片的呢?下图是Stable Diffusion生成图片的具体过程
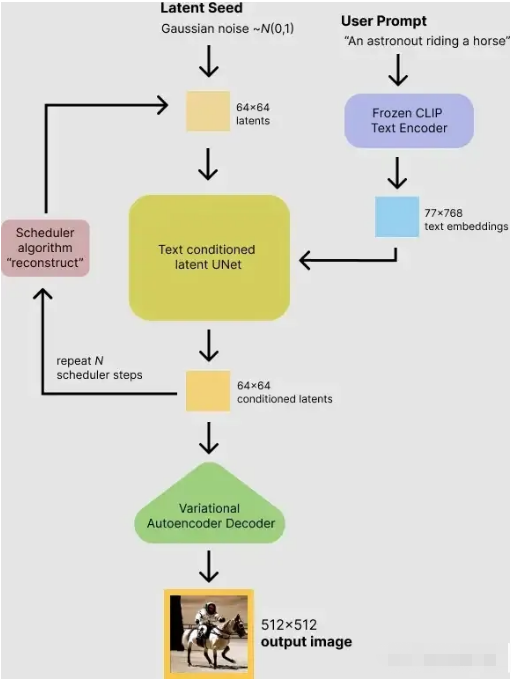
可以看到,对于输入的文字(图中的“An astronout riding a horse”)会经过一个CLIP模型转化为text embedding,然后和初始图像(初始化使用随机高斯噪声Gaussian Noise)一起输入去噪模块(也就是图中Text conditioned latent U-Net),最后输出 512×512 大小的图片。我们已经知道了CLIP模型和U-Net模型的大致原理,这里面关键是Text conditioned latent U-net,翻译过来就是文本条件隐U-net网络,其实是通过对U-Net引入多头Attention机制,使得输入文本和图像相关联,后面我们重点讲讲这一块是怎么做的。
2. Stable Diffusion的改进一:图像压缩
Stable Diffusion原来的名字叫“Latent Diffusion Model”(LDM),很明显就是扩散过程发生隐空间中(latent space),其实就是对图片做了压缩,这也是Stable Diffusion比Diffusion速度快的原因。
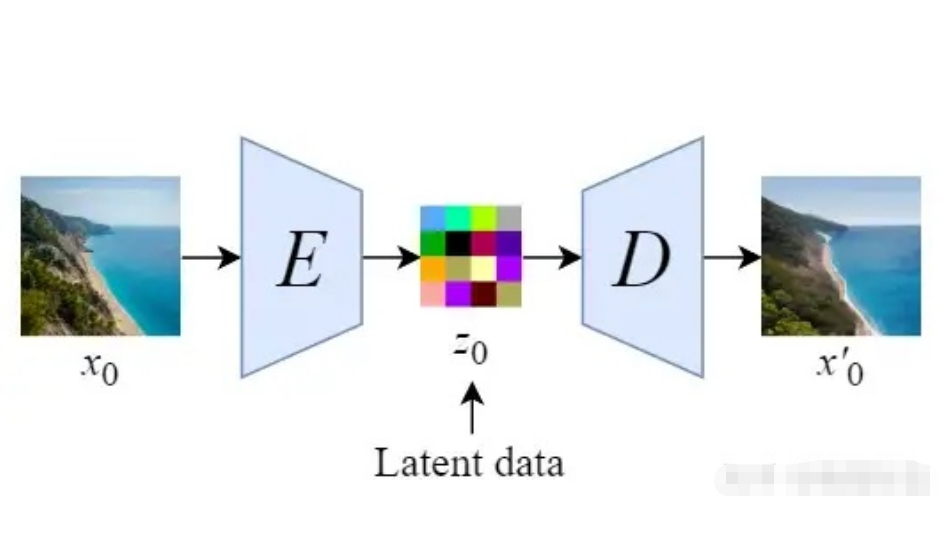
Stable Diffusion会先训练一个自编码器,来学习将图像压缩成低维表示。
通过训练好的编码器 E,可以将原始大小的图像压缩成低维的latent data(图像压缩)
通过训练好的解码器 D,可以将latent data还原为原始大小的图像
在将图像压缩成latent data后,便可以在latent space中完成扩散过程,对比下和Diffusion扩散过程的区别,如下图所示:
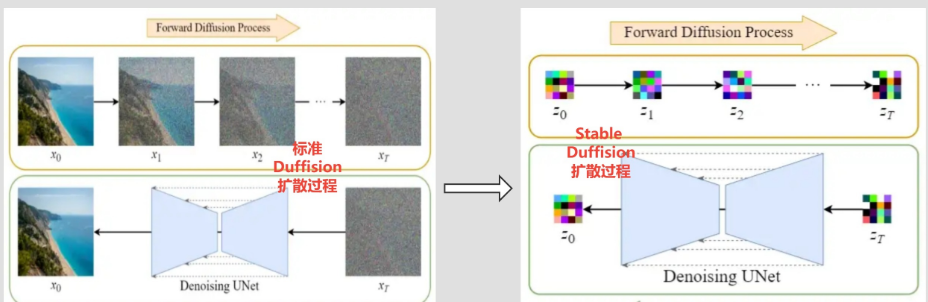
可以看到Diffusion扩散模型就是在原图 � 上进行的操作,而Stale Diffusion是在压缩后的图像 � 上进行操作。
Stable Diffusion的前向扩散过程和Diffusion扩散模型基本没啥区别,只是多了一个图像压缩,只是反向扩散过程二者之前还是有区别。
3. Stable Diffusion的改进二:反向扩散过程
在第一节我们已经简单介绍过Stable Diffusion文字生成图片的过程,这里我们扩展下,看一下里面的细节,如下图所示: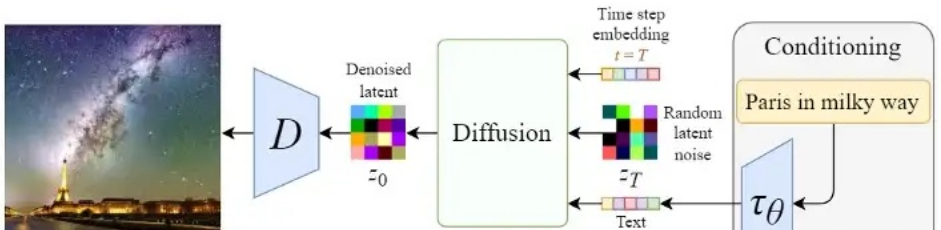
图从右至左,输入的文字是“Pairs in milky way”(银河系的巴黎),经过CLIP模型  转为Text embedding,然后和初始图像(噪声向量Zt )、Time step向量 T ,一起输入Diffusion模块(多轮去噪过程),最后将输出的图像
转为Text embedding,然后和初始图像(噪声向量Zt )、Time step向量 T ,一起输入Diffusion模块(多轮去噪过程),最后将输出的图像  经过解码器 D 后,生成最终的图像。
经过解码器 D 后,生成最终的图像。
Stable Diffusion在反向扩散过程中其实谈不上改进,只是支持了文本的输入,对U-Net的结构做了修改,使得每一轮去噪过程中文本和图像相关联。我们在介绍使用Diffusion扩散模型生成图像时,一开始就已经介绍了在扩散过程中如何支持文本输入,以及如何修改U-Net结构,只是介绍U-Net结构改进的时候,讲的比较粗,感兴趣的可以去看看里面的第一节。下面我们就补充介绍下Stable Diffusion是如何对U-Net结构做修改,从而更好的处理输入文本。
3.1 反向扩散细节:单轮去噪U-Net引入多头Attention(改进U-Net结构)
我们先看一下反向扩散的整体结构,如下图所示:
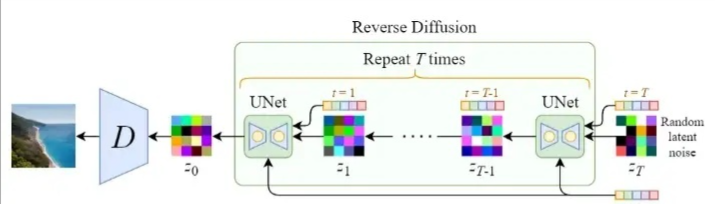
从上图可以看出,反向扩散过程中输入文本和初始图像Zt 需要经过 t 轮的U-Net网络( T轮去噪过程),最后得到输出 Z0,解码后便可以得到最终图像。由于要处理文本向量,因此必然要对U-Net网络进行调整,这样才能使得文本和图像相关联。下图是单轮的去噪过程:
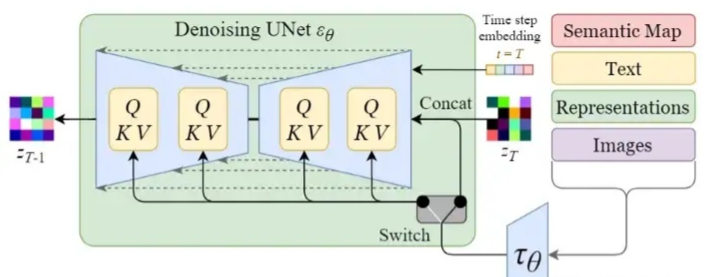
上图的最左边里面的Semantic Map、Text、Representations、Images稍微不好理解,这是Stable Diffusion处理不同任务的通用框架:
Semantic Map:表示处理的是通过语义生成图像的任务
Text:表示的就是文字生成图像的任务
Representations:表示的是通过语言描述生成图像
Images:表示的是根据图像生成图像
这里我们只考虑输入是Text,因此首先会通过模型CLIP模型生成文本向量,然后输入到U-Net网络中的多头Attention(Q, K, V)。
这里补充一下多头Attention(Q, K, V)是怎么工作的,我们就以右边的第一个Attention(Q, K, V)为例。
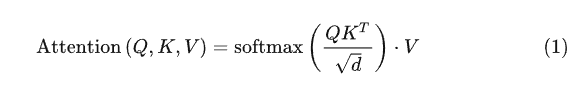
其中: 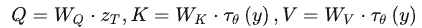 。可以看到每一轮去噪过程中,文本向量
。可以看到每一轮去噪过程中,文本向量 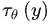 会和当前图像
会和当前图像 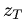 计算相关性。
计算相关性。
Stable Diffusion完整结构
最后我们来看一下Stable Diffusion完整结构,包含文本向量表示、初始图像(随机高斯噪声)、时间embedding,如下图所示:
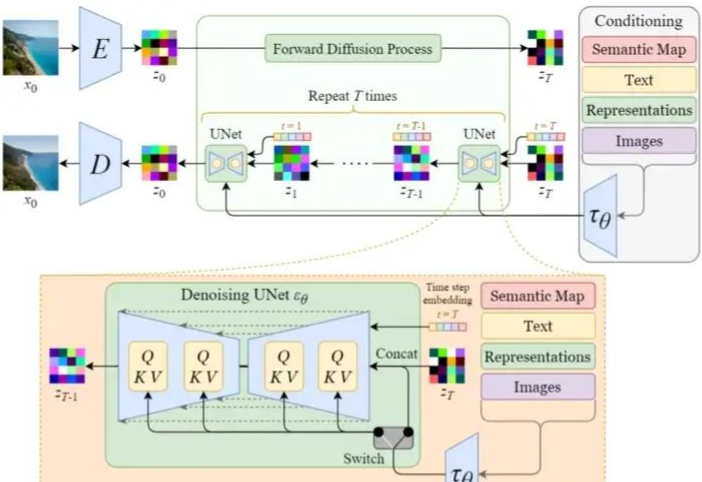
上图详细的展示了Stable Diffusion前向扩散和反向扩散的整个过程,我们再看一下不处理输入文字,只是单纯生成任意图像的Diffusion结构。
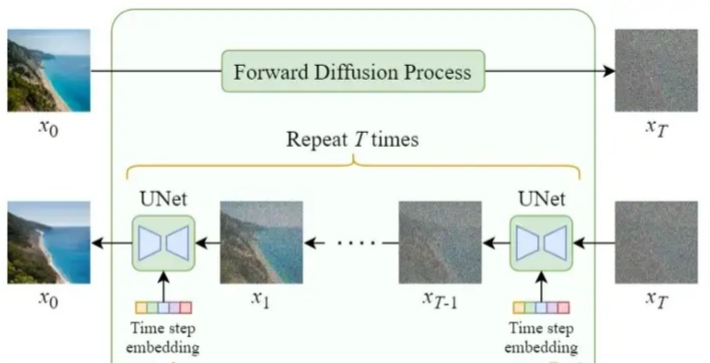
可以看到,不处理文字输入,生成任意图像的Diffusion模型,和Stable Diffusion相比,主要有两个地方不一样:
少了对输入文字的embedding过程(少了编码器 E、解码器 D )
U-Net网络少了多头Attention结构
总结
随着AIGC的爆火,各种应用开始不断出现,AI绘画便是其中的一个典型案例。目前最火的AI绘画模型当属Stable Diffusion,但是目前有关Stable Diffusion的文章并不多,主要偏向应用介绍,对于如何处理输入文字以及去噪过程的具体细节,这方面的文章还是比较少,写这篇文章的目的就是希望能把Stable Diffusion讲清楚,让更多人的了解。
原文出处:https://zhuanlan.zhihu.com/p/600251419
声明与鸣谢
部分内容来源于公开网络,版权归原作者所有,如有侵权,请留言告知我删除。
AIGC交流群
现已开放交流群,欢迎大家加入畅聊 AI,关注下方公众号即可免费进群。
